Datomic for Five Year Olds
If you're interested in Datomic, you may have been deterred from checking it out because you lack the enthusiasm necessary to slog through 3 keynotes, 8 interviews, and innumerable walls of text in order to get a basic idea of what the hell it is and whether you should use it.
Well, good news! I've done all that for you! How could I resist your winning smile, you charmer you? After you're done with this article, you will have a solid conceptual grasp of the three key ways that Datomic is unique. You will also understand key Datomic terms. This will make it much easier to actually get your hands dirty with Datomic if you decide to investigate it further.
Overview of Datomic's Three Righteous Pillars of Databasing
Datomic differs from existing solutions in its information model, its architecture and its programmability. Below is a quick overview. We'll cover each of these righteous pillars of databasing in much more detail.
| Relational DB | Schemaless DB | Datomic | |
|---|---|---|---|
| Information Model | The unit of information is an entity in a relation and you alter it in place, forgetting previous values | The unit of information is a schemaless document and you update it in place, forgetting previous values | The unit of information is a fact comprised of an entity, attributes, values, and time. You accrete the assertion and retraction of facts instead of updating in place. |
| Architecture | Database is a monolithic system responsible for querying, ACID compliance, and storage | Same as RDBMS | Separate querying, transacting, and storage in such a way that you get ACID compliance, read scalability, and more power within the application using Datomic |
| Programmability | Applications abstract SQL by performing string manipulation | Interact with proprietary data structures which are more programming-friendly than SQL but less powerful | Datalog, completely uses data structures and has as much power as SQL |
First Righteous Pillar of Databasing: Information Model
A database's information model is defined by its rules regarding the way entities and attributes relate to each other — for lack of a better term, its schema system.
Yea, the choice between a relational and schemaless database is probably your primary concern in choosing a database because of its influence on how you write and grow your programs. You'll see that Datomic's schema system isn't as rigid as the relational model but affords more power than a schemaless database.
Additionally, a database's information model is defined by its approach to time. Datomic's approach to time is different from most, if not all, existing databases.
Below are the schema systems for relational dbs, schemaless dbs, and datomic, followed by a comparison of the way the information models handle time.
Relational Schemas
You're probably already familiar with the relational model. Here are key definitions:
| Entity | An entity is tuple within a relation. It is comprised of a fixed set of attributes. In practice, an entity is a row in a table. |
| Attribute | A name + a data type. A column in a table. Attributes do not exist outside of relations. Attributes in different relations are always logically distinct, even if they hold the same type of data. |
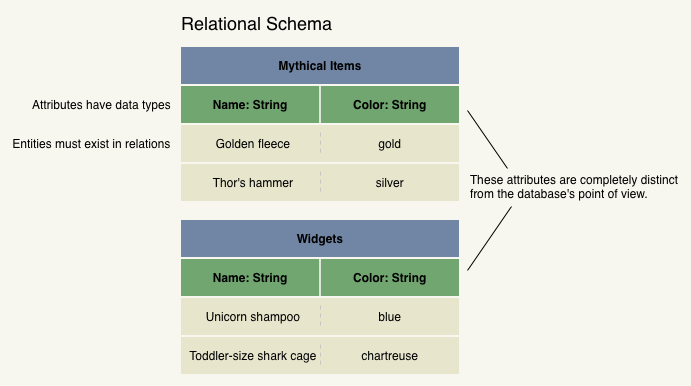
Probably the most important fact about the relational model is that it's rigid. Every entity must belong to a rigid relation. There's no way to add or remove attributes except by altering the structure of the relation, which in turn alters every other entity in that relation.
Schemaless
Schemaless (NoSQL) databases were created to address the rigidity of relational databases. They offer a few facilities for organization - for example, collections in MongoDB - but forego any structure for entities. This lack of structure comes at a cost: it limits your query power and forces data integrity concerns into your application.
| Entity | For our purposes, a document. A document has no restrictions on what attributes it can have. |
| Attribute | A name. Attributes can hold values of any type, and an attribute belonging to one entity is logically distinct from all other attributes, even those belonging to other entities within the same collection. Relationships between attributes are enforced within the client application. |

Datomic Schemas
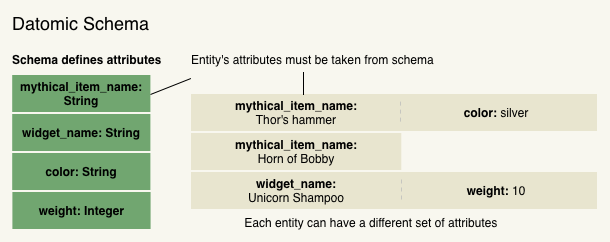
In Datomic, a schema defines a core set of attributes which effectively act as data types. An entity can possess any attribute without restriction. In this way, entities have more structure than a schemaless database but are more flexible than in relational databases. Additionally, you retain the query power of the relational model without having to handle data integrity concerns in your client applications.
| Entity | A map of attribute/value pairs. Entities have no fixed shape; they can be comprised of any attributes defined in the schema. |
| Attribute | Name + data type + cardinality. Attributes themselves can be thought of as data types. They differ from attributes in the relational model in that they exist independently of rigid tables |
Time
Datomic's notion of time might be unfamiliar for those unacquainted with Rich Hickey's thoughts on time and how it relates to identity, value, and state. To get up to speed, check out my article, "The Unofficial Guide to Rich Hickey's Brain"
In both relational and schemaless databases, there's no built-in notion of time. It's always "now" - the database doesn't hold on to the past. Whenever you update or delete a row, you have no way of retrieving previous states for that row.
This is the source of many headaches for us. If you've ever used or any code that requires multiple trips to the database in order to perform one unit of work, you know what I mean. In between each trip, you have no way of knowing whether the database has been been altered. You can end up writing all kinds of hacks to avoid race conditions and still not end up with a bulletproof system.
In addition, it's virtually impossible to query past states. You might not think this is really matters because you're used to the limitation, but being able to easily query past states is very powerful.
In Datomic, time is a first-class concept. All changes to the database are associated with a transaction, and each transaction has a timestamp. Rather than updating an entity in place and "forgetting" its previous state, datomic "accretes" states. In this way, you're able to retrieve all previous states for an entity.

Another way of thinking about it is that the database is an identity which we superimpose on a time-ordered collection of values. In this line of thinking, a "value" is the database as whole - its collection of entities and attributes. When you run a transaction which creates, updates, or deletes entities, you create a new database value. You're always able to say, "I want to work with the value of the database at this point in time."
Datomic's Information Model Summarized
In Datomic, the unit of information is a fact. A fact is comprised of an entity, an attribute, a value, and time. If you were to say "The princess", that would not be a fact. If you were to say, "The princess's favorite condiment", that would not be a fact. A fact would be "The princess's favorite condiment is mustard," that would be very close to a fact. "The princess's favorite condiment is mustard as of 10pm on February 10th." is a fact.
Facts don't go away. If the princess's tastes change so that she prefers sriracha, it's still useful to know that in the past she preferred mustard. More importantly, new facts don't obliterate old facts. In Datomic, all prior facts are available. Also, in Datomic, facts are called "datoms" and not "facts" because it's more exciting that way.
For more, check out The Datomic Information Model, an article by Datomic's creator, Rich Hickey.
Second Righteous Pillar of Databasing: Architecture
Existing databases couple the following into one monolithic product:
- Reading
- Writing
- Storage
Datomic decouples these capabilities. All writing is handled by a single "transactor", ensuring ACID compliance. This is the only point of similarity to existing solutions.
Side note: the diagrams at the Datomic Architectural Overview page are quite awful. Besides being ugly, it is difficult to tell what the visual components signify. What do the arrows mean? What does the dashed border mean? WTF is "Comm"? Please, please fix these. OK, rant over.
Your application communicates with datomic through the Peer Library, a component which exists within your applicaiton. Using the Peer Library makes your application a Peer. I think the Datomic guys were trying to avoid the term "client" here, but a Peer is essentially a client. What makes a Peer diffeerent from the usual database client, however, is that querying happens primarily in the Peer. By the way, when I say "querying" I mean "read querying."
Instead of sending a query "over there" to the database server, which runs the query and gives the client results, the Peer Library is responsible for pulling the "value of the database" into the Peer so that querying happens within your actual application. If you were to create a script out of this action-packed drama, it would look like:
- Peer: Peer Library! Find me all redheads who know how to play the ukelele!
- Peer Library: Yes yes! Right away sir! Database - give me your data!
- (Peer Library retrieves the database and performs query on it)
- Peer Library: Here are all ukelele-playing redheads!
- Peer: Hooraaaaaaaay!
The most novel thing here is "retrieves the database". In Datomic, you have the concept of the "value of the database" - the database as a whole, as a data structure. The Peer Library is responsible for pulling as much of that data structure into memory as necessary to satisfy your queries.
In this way, your queries run largely in your application rather than in a central database server, allowing for easy read scalability. It gives more power to your application rather than keeping all the power in a central server, where you have to worry about bottlenecks.
Finally, Datomic does not implement its own storage solution but instead relies on storage as a service, allowing you to choose which storage backend you use. Right now, the following backends are supported:
- The filesystem
- DynamoDB
- Riak
- Couchbase
- Infinispan
- SQL database
Third Righteous Pillar of Databasing: Programmability
In Datomic, everything is data! Your schema is data! Queries are data! Transactions are data! This is great because it's easier to manipulate data structures than it is to perform crazy string concatenation like you do with SQL. Check out these example queries.
Resources
- The Design of Datomic
- Rich Hickey on Datomic
- The Value of Values
- The Datomic Information Model
- Datomic docs
The End
That's it for now! If you have any suggestions or corrections please let me know.